Quando il numero di Permutazioni è eccessivo, oppure si hanno variabili di difficile stima, studiare un fenomeno in maniera analitica è praticamente impossibile. Per tale motivo si usa il “Metodo Monte Carlo“.
Si prenda ad esempio il tiro con l’arco. Conoscendo il peso e la forma della freccia, la quantità di moto iniziale ecc è possibile (grazie alla Fisica Classica) calcolarne il punto di impatto. Tra i parametri da considerare, però, vi sono l’emotività del tiratore, la stanchezza, le tolleranze dell’arco e delle frecce le condizioni atmosferiche (vento) ecc: lo studio analitico è piuttosto complesso.
Un fenomeno che dipende fortemente dalle condizioni iniziali ( si veda la “Teoria del caos“) può essere studiato con approccio statistico.
Si considerano quindi le variabili come “Aleatorie“. Un fenomeno aleatorio, a differenza di quello deterministico, non porta sempre allo stesso risultato. Il lancio di un dado ne è l’esempio per antonomasia: il risultato varia di volta in volta.
Il dado, infatti, “tira fuori” un numero secondo una distribuzione probabilistica (P.D.F.) uniforme , ovvero quell’elemento ha la stessa probabilità degli altri di essere selezionato e non dipende da chi tira, da come tira ECC.
Problemi legati alla generazione di “valori casuali“
Si tenga presente che la generazione di un “valore” casuale non è così scontata. Un processore infatti può compiere miliardi di operazioni al secondo ma solo “di tipo algebrico. Il programmatore gestisce tale potenza di calcolo impartendo “istruzioni”. Non è possibile quindi, concettualmente, che il processore fornisca un numero casuale!
Daltronde non esiste un sistema più deterministico di un processore: con gli stessi dati in ingresso restituisce (return) sempre gli stessi risultati.
Molti software, infatti, sfruttano degli algoritmi ma tirano fuori comunque valori riproducibili: si tratta quindi di un processo “Pseudorandom“. Per avere numeri realmente casuali è necessario ricorrere a “Generatori hardware di numeri casuali“, basati su “rumori” fisici (rumore termico , decadimento raioattivo ecc) che, proprio per loro natura, sono casuali.
Quelli utilizzati in questa sede sono dunque dei ” PRNG” ( pseudorandom number generator ).
Distribuzione probabilistica P.D.F. e relativa cumulativ C.D.F.
Esistono diverse distribuzioni probabilistiche. Come esempio si può richiamare la distribuzione probabilistica di Gauss, detta anche “normale”, che viene descritta come:

Ove 

Una semplice funzione in Python implementa tale funzione:
#Costruzione PDF
def PDF(x,sig,xc,k):#(x, sigma, valore centrale, passi)
a = 1/(pow(2*np.pipow(sig,2),0.5))
pdf = np.zeros(k)
for i in range(0,k):
pdf[i] = a*math.exp(-pow(x[i]-xc,2)/(2*pow(sig,2)))
return pdf
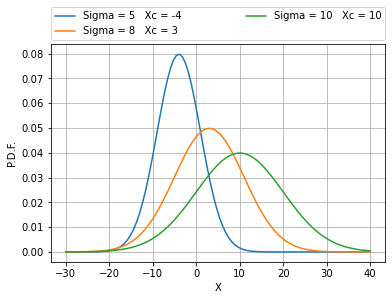
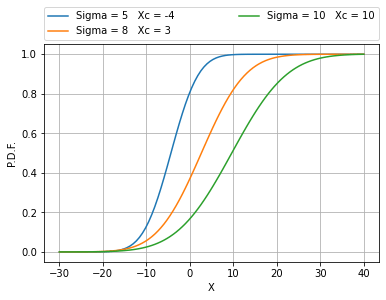
Per questioni di calcolo numerico, si è reso necessario “quantizzare” la P.D.F., ovvero la variabile x è stata discretizzata (in K passi). L’integrale della P.D.F. porta alla distribuzione probabilistica cumulativa C.D.F.. Nel discreto, un integrale si riduce ad una semplice sommatoria:
#Costruzione CDF
def CDF(pdf,k):
cdf = np.zeros(k)
cdf[0] = pdf[0]
for i in range(1,k):
cdf[i] = cdf[i-1]+pdf[i]
cdf = cdf/max(cdf)#Normalizzazione CDF
return cdf
Lancio del dado
Il lancio del dado, o meglio i lanci (servono migliagli di lanci), verrà simulato grazie al modulo “random” di Python (si tratta quindi di PRNG).
import random
#Estrazione da distribuzione uniforme 0-1
def dado(): return np.random.uniform(0,1)
[…]
r = dado() #lancio del dado
[…]“Alea iacta est!”
Quindi si vuole avere una distribuzione di probabilità uniforme, ovvero ogni “faccia” ha la medesima probbilità di essere estratto (1/6).
Nota: si tratta di distribuzioni quantizzate. I numeri estratti, ovviemente, sono solo interi. Non è possibile lanciare un dado e ottenere 1,3….
Il modello di distribuzione è riportato in seguito.
facce = [1,2,3,4,5,6]#Facce del dado
PDF =(1/6)* np.ones(6)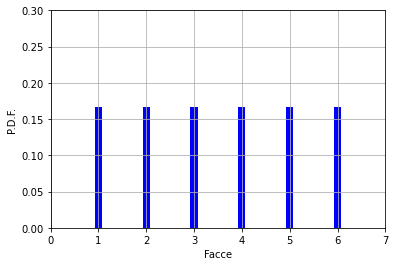
A cui è associata una distribuzione probabilistica cumulativa C.D.F.
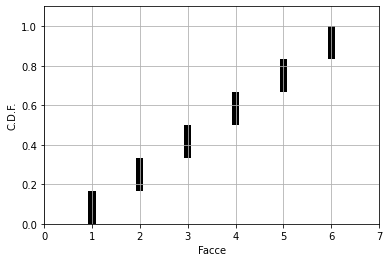
Notare che la C.D.F. deve avere come valore massimo 1: questo perchè, data la distribuzione probabilistica (P.D.F.), la somma delle probabilità che un evento accada deve coincidere con l’unità. In sostanza, si ha il 100% di probabilità che un valore venga estratto (lanciando il dato non è concepibile che rimanga fermo su uno spigolo).
Il dato di ingresso è il risultado dell’estrazione di una variabile aleatoria a distribuzione uniforme r. Entrando nella C.D.F. si ottiene il relativo valore estratto.
def estrazione(cdf):
r = dado() #estrazione
if(r<= CDF[0]):
p = 0
for i in range(1,6):
if(r<= CDF[i] and r > CDF[i-1]):
p = i
return pIn p viene quindi memorizzato l’indice della faccia estratta.
Ad esempio, se venisse estratto il valore 0,6 il risultato sarebbe “4”, OPPURE SE VENISSE ESTRATTO IL VALORE 0,25 IL RISULTATO SAREBBE “2”:
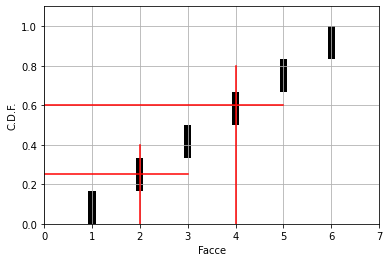
Se si procedesse al’estrazione di un numero virtualmente infinito di valori e si calcolasse, grazie ai risultati, la probabilità che un evento avvenga, si otterrebbe proprio la P.D.F. Ad esempio, si conta il numero delle volte in cui è stao estratto il numero 4 e si divide per il numero N di estrazioni.
METODO MONTE CARLO - n iterazioni
contatore = np.zeros(6)
for i in range(0,n):
estratto = estrazione(CDF)#estrazione da CDF
contatore[estratto] +=1
pid_r = contatore/n#valore probabilità "ricostruita"Il codice completo:
import numpy as np
import matplotlib.pyplot as plt
import math
import random
n = 10000 #numero estrazioni
#Ritorna il valore estratto
def dado(): return np.random.uniform(0,1)
#estrazione di un valore contenuto in v in funzione della
#relativa CDF
def estrazione(cdf):
r = dado() #estrazione
if(r<= CDF[0]):
p = 0
for i in range(1,6):
if(r<= CDF[i] and r > CDF[i-1]):
p = i
return p
facce = [1,2,3,4,5,6]#Facce del dado
PDF =(1/6)* np.ones(6)
#Costruzione CDF
CDF = np.zeros(6)
CDF[0] = PDF[0]
for i in range(1,6):
CDF[i] = CDF[i-1]+PDF[i]
METODO MONTE CARLO - n iterazioni
def monte_carlo(n):
contatore = np.zeros(6)#azzeramento contatore
for i in range(0,n):
estratto = estrazione(CDF)#estrazione da CDF
contatore[estratto] +=1 #se estratto, incrementa!
return contatore/n #valore probabilità "ricostruita"
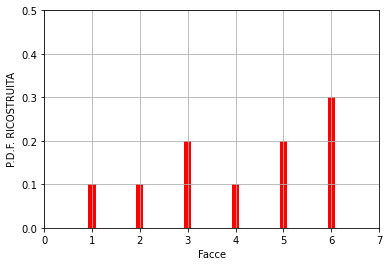
pid_r = monte_carlo(n)#chiama l'algoritmo "Monte Carlo" Il risultato:
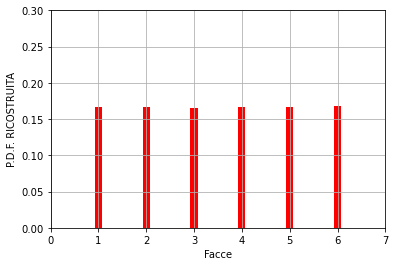
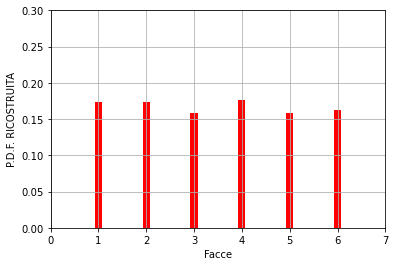
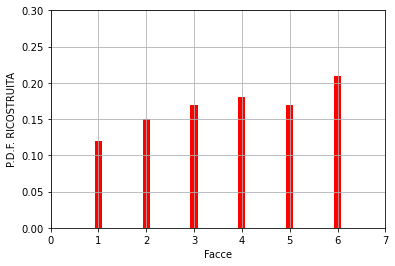
Questo risultato è stato ottenuto con un numero di estrazioni n = 100000. Riducendo “n”, la P.D.F. RICOSTRUITA approssimerà sempre meno quella di partenza. Di seguito alcuni esempi.
n=1000
n = 100
n = 10
Daltronde non ci si potrebbe aspettare diversamente. Portando all’estremo il ragionamento tentando un solo lancio, il valore ottenuto “mostrerebbe” una probabilità del 100%. Questo sarebbe assurdo.
n = 1
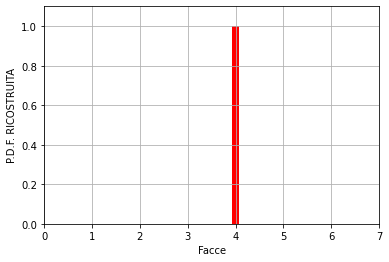
Inoltre, con “n” eccessivamente basso, il risultato varia continuamente ad ogni simulazione. Si prenda, ad esempio, la faccia numero 4.
[...] C.D.F calcolata a monte [...]
#METODO MONTE CARLO - n iterazioni
def monte_carlo(n):
contatore = np.zeros(6)
for i in range(0,n):
estratto = estrazione(CDF)#estrazione da CDF
contatore[estratto] +=1
return contatore[4]/n #probabilità del solo numero "4"!
k = 100 #numero simulazioni per ogni valore di n
P_n_10000 = np.zeros(k)
P_n_1000 = np.zeros(k)
P_n_100 = np.zeros(k)
P_n_10 = np.zeros(k)
P_n_1 = np.zeros(k)
#nota: monte_carlo(), in questo caso, non ritorna "contatore/n"
#ma solamente "contatore[4]/n"
for i in range(0,k):
P_n_10000[i] = monte_carlo(10000)
P_n_1000[i] = monte_carlo(1000)
P_n_100[i] = monte_carlo(100)
P_n_10[i] = monte_carlo(10)
P_n_1[i] = monte_carlo(1)
Notare come la probabilità calcolata subisca maggiori variazioni, durante i vari tentativi, per valori di n bassi. Aumentando n, infatti, si osserva che la differenza tra il risultato ottenuto e quello reale diminuisce (varianza) e le curve tendono ad appiattirsi.
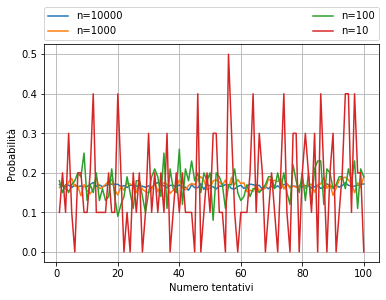
Con questo si è voluto dimostrare che il “singolo dato” è decisamente inutile ai fini statistici.
Calcolo della probabilità con il Metodo Monte Carlo
Ipotizzando di avere due valori conosciuti però non in maniera deterministica ma con tolleranza. Per esempio A = 3 e B = 4. Di questi due valori si conoscono le distribuzioni probabilistiche C.D.F. (cumulative):
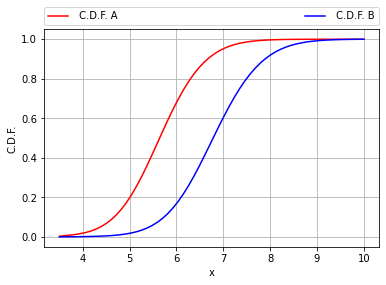
Volendo calcolare quale sia la probabilità che, estraendo i valori A e B dalle rispettive cumulative, il loro prodotto C rispetti la condizione:

Si simulano n lanci (es. n = 100), come in esempio:
#Funzione costruzione PDF
def PDF(x,sig,xc,k):#(x, sigma, valore centrale, passi)
a = 1/(pow(2*np.p*ipow(sig,2),0.5))
pdf = np.zeros(k)
for i in range(0,k):
pdf[i] = a*math.exp(-pow(x[i]-xc,2)/(2*pow(sig,2)))
return pdf
#Funzuone costruzione CDF
def CDF(pdf,k):
cdf = np.zeros(k)
cdf[0] = pdf[0]
for i in range(1,k):
cdf[i] = cdf[i-1]+pdf[i]
cdf = cdf/max(cdf)
return cdf
def dado(): return np.random.uniform(0,1)#Ritorna il valore estratto
#estrazione di un valore contenuto in v in funzione della
relativa CDF
def estrazione(cdf, k):
r = dado()
if(r<= cdf[0]):
r_v = 0
for i in range(1,k):
if(r<= cdf[i] and r > cdf[i-1]):
r_v = i
return r_v
PDF_A = PDF(x,sigma_A, A, K)
PDF_B = PDF(x,sigma_B, B, K)
CDF_A = CDF(PDF_A,K)
CDF_B = CDF(PDF_B,K)
plt.plot(x,CDF_A ,color = "red",label =" C.D.F. A")
plt.plot(x,CDF_B ,color = "blue",label =" C.D.F. B")
plt.ylabel("C.D.F.")
plt.xlabel('x')
plt.legend(bbox_to_anchor=(0., 1.02, 1., .102), loc='lower left', ncol=2, mode="expand", borderaxespad=0.)
plt.grid()
plt.show()
n = 1000
cont = 0
for i in range(0,n):
a = estrazione(CDF_A,K)
b = estrazione(CDF_B,K)
plt.scatter(x[b],x[a],color ="red",s = 1.2)
c = x[b]*x[a]
if(c < 1.5*A*B and c > 0.9*A*B):
cont += 1 #Volte in cui si verifica la condizione richiesta
plt.plot(x,0.9AB/x ,color = "black",label ="ab = 0.9AB") plt.plot(x,1.5AB/x ,color = "blue",label ="ab = 1.5AB")
plt.ylabel("A")
plt.xlabel("B")
plt.legend(bbox_to_anchor=(0., 1.02, 1., .102), loc='lower left', ncol=2, mode="expand", borderaxespad=0.)
plt.grid()
plt.show()
Prob = 100cont/n risultato = "La probabilità che 0.9*AB < C < 1.5*A*B " + str(Prob) + "%"
print(risultato) 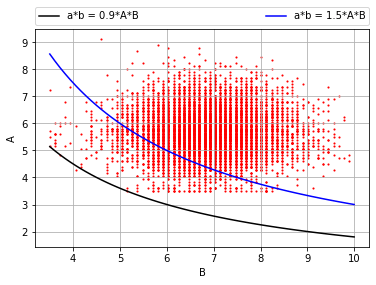
La nuvola di punti è costituita dalle coppie (a,b) di valori estratti. Il rapporto tra i punti compresi tra le due curve (condizioni limite) e il numero di punti totali ci da la probabilità che la suddetta condizione si manifesti.
Il risultato (output) è il seguente:
“La probabilità che 0.9AB < C < 1.1AB è del 9.79%”
Applicazioni
Una delle applicazioni del Metodo Monte Carlo è la progettazione e lo studio delle reti elettriche, in particolare in presenza di generazione locale.
Considerando infatti un generatore eolico, la potenza prodotta è proporzionale alla velocità del vento, che a sua volta è un parametro aleatorio. Considerando un certo periodo dell’anno ad un certo orario, si ha una C.D.F. determinata dai dati ottenuti da prolungate campagne di misura:
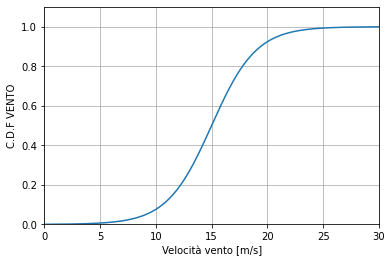
Il costruttore fornisce i dati necessari a stimare la potenza generata in funzione della velocità del vento.
Quindi, supponendo di avere una rete che coinvolga differenti generatori , per determinare le correnti che passano nei vari tratti di linea, si procede con il Metodo Monte Carlo:
Si imposta un numero di iterazioni sufficientemente alto (esempio n =1000) e per ogni iterazione si estrae un valore di r (da una distribuzione probabilistica uniforme) a cui è univocamente associata (grazie alla C.D.F.) una velocità del vento.
Un calcolo più accurato, deve tener conto della disponibilità del generatore. Si ha probabilità 

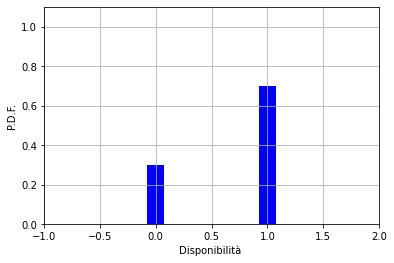
Quindi, ricapitolando, si “estrae” la disponibilità e poi si “estrae” la velocità del vento (ergo, la potenza generata). Questo in ogni iterazione e per ogni generatore, per poi calcolare le correnti sulle linee (tenendo presenti i carichi ecc. con il metodo del load flow).
La “media” di tutte le correnti risultanti è la corrente con cui si dimensionano o si verificano le linee.
Il metodo trova utilità in ambito di “sicurezza“: per calcolare il fattore di sicurezza Fs per quanto riguarda la caduta massi, ad esempio, i dati in ingresso sono “aleatori”: peso del masso, inglinazione delle superfici di scorrimenti, angolo di attrito, attrito delle superfici ecc. Tutti parametri che deve fornire un geologo. La “fisica” è nota ma i parametri e le condizioni iniziali sono dunque casuali. Si procede a numerore estrazioni di tali valori per poi calcolare ogni volta il risultato. Doi numerosi risultati si ricava la “freauenza” con cui il risultato viola i parametri di sicurezza, ovvero (nel complesso) si va sotto il noto “fattore di sicurezza”.
Matteo Gentileschi
